

 资讯
资讯每当(dāng)看到人工智能(也(yě)即AI),我们通(tōng)常会想到机器(qì)人(rén)、自动化、图像语音(yīn)或视频识别、算法等高大(dà)上的黑(hēi)科技。而对象存储则给人一种低调、海量的感觉。是什么(me)原因,让这两者相遇,并擦出了(le)火花?
什(shí)么是对象(xiàng)存储?
对象存储是自包(bāo)含、自愈合的智(zhì)能存储(chǔ)设备,具有容量大、速度快、扩展灵活的特(tè)点(diǎn)。每一个对象除了(le)存放数据本身之外(wài),还存(cún)放了标识符和数据的元信息,例如创建的日期和时间,属主(zhǔ),大(dà)小,索引,保留周期,QoS等。对象(xiàng)本(běn)身使得数据(jù)的组织得到(dào)了简化(huà),避免了传统(tǒng)存储文件目(mù)录树形(xíng)结构的复杂。对象的存放(fàng)是(shì)扁(biǎn)平(píng)化地方式保存在(zài)bucket(桶)中(zhōng)的,变得更简单。而且对象(xiàng)的元信息,也方便(biàn)了检索。
拿生活中常见的例子(zǐ)来比喻,当图书馆购进新的纸(zhǐ)质(zhì)书籍(jí)需要存放时,需要按(àn)照图(tú)书分类法(按照(zhào)图书的内容、形式(shì)、体裁和(hé)读者用途等进行(háng)分类),清楚地知道大类、子类和更详细的分类,才能(néng)找(zhǎo)到合(hé)适的(de)位(wèi)置上架。文件存储的数据存放就(jiù)类似图书(shū)分门别类地存放(fàng),如下图。

类比:文件存储的数(shù)据(jù)存放方式就(jiù)像图书分类
当我们逛超市需(xū)要存包的时候,尽管有那么多储(chǔ)物柜,但是大(dà)家都觉得存取包很简单(dān)。存的时候(hòu),按(àn)一下存包(bāo)按(àn)键(jiàn),啪的一(yī)声,一(yī)个柜子打(dǎ)开,同时你会得到包(bāo)含二维码的纸条,你把包放到柜子(zǐ)里,但是不用记(jì)住柜(guì)子的位置和编号,潇(xiāo)洒的(de)离开。当你取(qǔ)包的时候,你刷一(yī)下二(èr)维码,也是啪的一声,放包(bāo)的柜子自动打(dǎ)开,所(suǒ)存物(wù)品唾手可(kě)得。对象存储的数据存放方式就和超(chāo)市存取包很类似,存储对(duì)象的标识符就相当于(yú)那个(gè)二(èr)维码。

类比(bǐ):对象存储的数据存放方式就(jiù)像超市存包
下图是(shì)对象存(cún)储的一些特(tè)点。

对(duì)象存储特点
不过,我们需要注(zhù)意的是,文件存储和对象(xiàng)存储有着各自适用的场景(jǐng)。下图列出了分(fèn)布式(shì)文件存(cún)储(chǔ)和分布式(shì)对象存储的区(qū)别(bié):

分布式文件存储与分布式(shì)对象存(cún)储的(de)区别
当(dāng)文件数量级过亿的(de)时(shí)候,文件目(mù)录树(shù)形结(jié)构会(huì)对数据的(de)读写造成巨大的挑战,例(lì)如在linux中如果用ls查看(kàn)文(wén)件,可能都要(yào)等待几十分钟以上。但是,量级没有如(rú)此(cǐ)之大时,因为过去的(de)使用习惯,以及(jí)相对成熟的生(shēng)态,使用文件存储还(hái)是不错的(de)选择(zé)。
如何(hé)避免错误(wù)理解对象存(cún)储
当我们谈对(duì)象(xiàng)存(cún)储时,需要注意讨论的是存储接口,还(hái)是内部数据组织形式。
1)实际上,讨论对象存储大多数是指存(cún)储接口,是否支持RestFul或S3,也即对象接口的形式来访问(wèn)存储空间。
2)少数情况下,对(duì)象存储指(zhǐ)存(cún)储设备的内部数据组织形式。在(zài)数(shù)据猛增的(de)背景下,越来越多的存储设备(bèi)内部(bù)采用对象存(cún)储(chǔ)的这种内部数(shù)据组(zǔ)织形式(shì)。例如VMwarevSAN,其实是(shì)是(shì)一种基于服务器端存储的共享分布式(shì)对(duì)象存储(chǔ)系统,只(zhī)不过存(cún)储接口主(zhǔ)要(yào)采用的是SCSI方式;或者具备高可(kě)靠(kào)、高性能、高安全和易管理的浪潮AS13000,如下图。
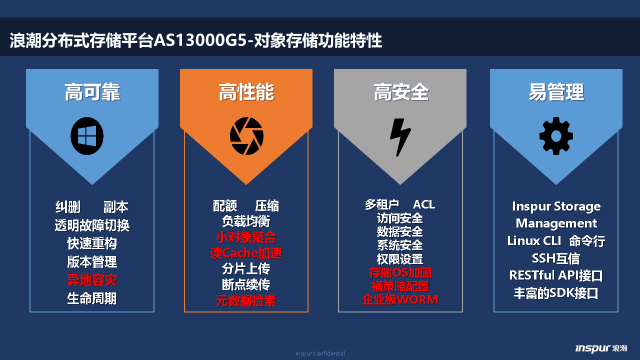
浪(làng)潮AS13000G5的对(duì)象存储功能(néng)
AI与对象存储
在许(xǔ)多人的印象中,AI需要大量(liàng)的算力(lì),是(shì)计算密集型的典(diǎn)型应用。而(ér)对(duì)象(xiàng)存储大多时候用于海量非结构(gòu)化数据的存放(fàng),备(bèi)份归档,云存储、企业云盘(pán)、文档影像或(huò)视频(pín)的存储等。从存储特征(zhēng)来看(kàn),对象存储(chǔ)的延(yán)迟可能较难满足AI的(de)性能(néng)需求;从使用习惯来(lái)看(kàn),大(dà)多数AI用户(hù)都是(shì)采用(yòng)文件(jiàn)接口。
实际上,有计算,就会有(yǒu)存储,只是或(huò)多或少,或快或慢(màn),或过渡或长期保存的区(qū)别。
在微(wēi)信公众号浪潮(cháo)存储《2020:下一个(gè)十年,存储发展的(de)趋势是什么(me)》上篇也即鉴往事篇(piān)一文中,曾(céng)提到:
AI所需存储,可(kě)以分(fèn)为准备、训练、推理和归档等阶段(duàn),每个阶(jiē)段的IO特征不一样,对于存储(chǔ)的要求也不一样。例(lì)如,在推理阶段,IO的特征是读写混合,并且要(yào)求存(cún)储的延时低,能快(kuài)速响(xiǎng)应。
下图列(liè)出了AI各个阶段(duàn)的IO特征,及其(qí)对(duì)存储的(de)要求(qiú)。
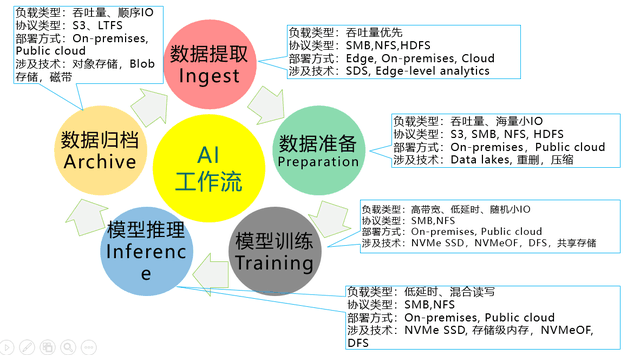
AI各个阶(jiē)段的IO特征及存储(chǔ)需求
综合考虑用(yòng)户使用习惯、性价比、性能和容量,如果(guǒ)能够取得(dé)一个(gè)平衡的话,对象存(cún)储(chǔ)能够用在(zài)AI的(de)多个不同阶段(duàn)中,如提(tí)取(qǔ)、准备、训练、归(guī)档等。
NVIDIA收购SwiftStack用(yòng)来做什么呢?
首先,我们(men)来看(kàn)一下做为事实上的标准的AWSS3,从骨子里说(shuō),它(tā)代(dài)表(biǎo)的对象存储(chǔ),是一种在(zài)线(xiàn)的海量数据较低成本的存(cún)储方式,适合跨地域读写(xiě);因此,虽然备份归档是对象(xiàng)存(cún)储的(de)使用场景之(zhī)一,但只是做备份归档,其实是(shì)委屈(qū)了对象(xiàng)存储。
其次,对象存储的(de)高(gāo)并发,特别适合前端呈(chéng)现(xiàn)分布式负载的场(chǎng)景。AI场景的使(shǐ)用,包括AI训练、AI推理,是由许许多多个任务并发进行的,任务与任(rèn)务之间几乎没有数据(jù)的交互,因此很少考虑存储通常要顾及的写一致性。
因(yīn)此,在(zài)我们看来,NVIDIA收购SwiftStack或许有如下几个(gè)原因:
1)NVIDIA欲整合AI基础架构
NVIDIA是一(yī)个非(fēi)常注重(chóng)生态的(de)公司,它的版图里(lǐ)应(yīng)该不仅仅是计算以及衍生出来的(de)各个组件(jiàn),从(cóng)近(jìn)两年的(de)动作来看,NVIDIA想(xiǎng)整合整个AI基础架构。2019年3月11日NVIDIA以69亿美元收(shōu)购Mellanox;2020年3月6日宣布收购SwiftStack。
2)SwiftStack具备数据跨(kuà)云管(guǎn)理和高并发的优(yōu)势
据报道:"ManuvirDas表示,NVIDIA尤其喜欢SwiftStack的1space技术,该技术可以为忙于处理缓(huǎn)存(cún)和分(fèn)层等任务的GPU助一臂之力。
SwiftStackV7于2019年(nián)发(fā)布,提供数PB的(de)规(guī)模(mó),可处理数千(qiān)个worker节点同(tóng)时访问数据的任务(wù)。它(tā)提(tí)供了超过100GB/秒的吞吐(tǔ)速度,性(xìng)能(néng)和容量都能实现线(xiàn)性扩展。
1space是NVIDIA收购Swiftstack的主要原因,这是一种文件连接件,使云原(yuán)生应用(yòng)程(chéng)序可以通(tōng)过S3或Swift对(duì)象(xiàng)API访问(wèn)本地(dì)数(shù)据或AWS数据(jù),并可以确保不断向数据提供(gòng)计(jì)算(suàn)资源”
我个人认为,AI训练有个特点,它一次性将原始训练集的数据加载到计算节点的(de)内(nèi)存或者SSD后,需(xū)要经过一段(duàn)较长的时间(也即计算或说训练),才会再次读取存储上(shàng)的(de)数据。因此,对(duì)象存储的延迟可能(néng)不会构成障(zhàng)碍,这一点(diǎn)可以通过高并发来弥补。
3)还可(kě)将(jiāng)SwiftStack用于数据(jù)提取(qǔ),或者数据归档阶段。海量的(de)数据,采用对象存储(chǔ)是一个不错的选择。
4)维护原有使用习惯
NVIDIA内部(bù)大量(liàng)使用SwiftStack来(lái)存储数(shù)据,几年下(xià)来(lái),习(xí)惯(guàn)已经(jīng)养成,而且猜测数据量也非常庞大(dà)。通过收购SwiftStack,以免未来受(shòu)人(rén)制肘(zhǒu),也是有可能的。
无论如何,对(duì)象(xiàng)存储在云计算和AI迅猛(měng)普及的情(qíng)况下,一定会迎(yíng)来它的春天。IDC中国SDS市场数据显示(shì),2019年对象存储增长率(lǜ)55.3%,是(shì)中国(guó)软件定义存储市场里增速(sù)快的细分领域(yù)。
在中国的对象存储(chǔ)市场中,浪潮的AS13000做(zuò)出了贡(gòng)献。2019年,AS13000对象存储成功地在某银行(国(guó)内排名(míng)前(qián)15)总行的影像系统中部署,并实现了同城容灾功能。如下图所示(shì):

浪潮AS13000对(duì)象存储的实际案(àn)例(lì)
浪潮分布式存储在不(bú)断迭代的过程(chéng)中,除了前面提到的同城容灾之外,还开发了大量的(de)其他高级(jí)特性。一是(shì)小对象(xiàng)聚合(hé)。浪潮对象存储针(zhēn)对海量小文件场景,通(tōng)过小对(duì)象聚合,节约HDD的磁盘IO,提升存储效率。二是(shì)读Cache加速。在卡(kǎ)口图(tú)片(piàn)、AI计(jì)算场景,通过读Cache加速提升数据读取效率。三是元数据检索。在存储系统(tǒng)内集成索引引(yǐn)擎,实(shí)现根据对象元数据(jù)多条件模糊检(jiǎn)索对象的技术,有(yǒu)效地提(tí)升了(le)海量非结构化数(shù)据中(zhōng)“大海捞针”的效率。四是企业级WORM,满足企业客户数(shù)据(jù)的法规性要(yào)求,结合应用特(tè)点,灵活设置宽限期(qī)和保护期。此(cǐ)外,还有存储OS加固(gù)、桶策略配置等等。
展(zhǎn)望未来
受“新冠疫情”影响,在线化(huà)、数字化、分散化、自(zì)动化等新形态新模式,也对AI、大数据中心(含计算、存储(chǔ)、网络(luò)和安全)等的发展提出了迫(pò)切的需求。
疫情趋(qū)势预(yù)测、风(fēng)险预警、医疗资源和物质的(de)预测(cè)和调配,要做(zuò)到快速、准确、科(kē)学(xué)的判断,需要(yào)和AI结合。
另外,非接触(chù)的服务和(hé)工作、自(zì)动化、快速分(fèn)析(xī)决策(cè)和(hé)响应的需求等,将会爆发。例如,人脸识别(包(bāo)括免摘(zhāi)口罩的人脸识别)、AI辅(fǔ)助(zhù)诊断(duàn)、应(yīng)急(jí)管理、安防(fáng)监控(kòng)、知识图谱、基因研究、医药研发(fā)、金融服务、智(zhì)能配送、各行各业的无人值守(例(lì)如零售)、物(wù)流运输、个人画像(xiàng)、轨(guǐ)迹追踪、舆情分析等等。
我们相(xiàng)信,作为新基建的一部分,包含AI和存(cún)储在(zài)内的信息基础设(shè)施将迎来更好(hǎo)更快的发(fā)展。










络警察")
")
良信息举报中心(xīn)")
